Here is the simple topology for this lab. R1 and R2 are on VLAN 12. VLAN12 needs to be IPv6 only. We test this my assigning IPv4 and IPv6 addresses to both routers and then pinging.
R1---SW1---SW2---R2
R1:
IPv4: 192.168.12.1/24
IPv6: 2001::1/64
R2:
IPv4: 192.168.12.2/24
IPv6: 2001::2/64
Making a vlan IPv6 only requires more configuration than I previously thought. This was my first attempt. On all switches:
mac access-list extended IPv6
permit any any 0x86DD 0x0
vlan access-map IPv6only 10
action forward
match mac address IPv6
vlan filter IPv6only vlan-list 12
So R1 pings R2:
R1#ping 192.168.12.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.2, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
R1#ping 192.168.12.2
But wait, let's remove the filter, ping, add the filter back, and ping again.
SW1(config)#no vlan filter IPv6only vlan-list 12
R1#ping 192.168.12.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/3/4 ms
SW1(config)#vlan filter IPv6only vlan-list 12
R1#ping 192.168.12.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/2/4 ms
R1 can still ping. What happened? Well the original filter wasn't blocking IP, it was only blocking ARP packets. Remember MAC access-lists do not have an implicit deny for the IP ethertype but they do have an implicit deny for all the other ethertypes. So once we removed the filter and allowed ARP through, R1 was able to ping R2 when the filtered was applied.
To make the vlan IPv6 only I had to specify a drop action in an empty access-map statement:
SW1(config)#vlan access-map IPv6only 20
SW1(config-access-map)# action drop
R1#ping 192.168.12.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.2, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
R1#
But wait, let's check out spanning-tree:
SW1#sho spanning-tree vlan 12 | inc root
This bridge is the root
SW2#show spanning-tree vlan 12 | inc root
This bridge is the root
This is bad because both switches forward out all ports when they think they are root. If we had multiple links between these switches, we would have a loop. You may start seeing these messages:
SW2#
01:28:49: %SW_MATM-4-MACFLAP_NOTIF: Host 00b0.6410.3901 in vlan 12 is flapping between port Fa0/13 and port Fa0/14
01:28:49: %SW_MATM-4-MACFLAP_NOTIF: Host 0007.eb14.4f81 in vlan 12 is flapping between port Fa0/13 and port Fa0/14
We need to allow STP bpdu's in our original MAC access-list. Do this now:
SW1(config)#mac access-list extended IPv6
SW1(config-ext-macl)#permit any any lsap 0xAAAA 0x0
Now we see SW2 blocking on the port f0/14 (for VLANs 1 and 12):
SW2#sho span | inc BLK
Fa0/14 Altn BLK 19 128.16 P2p
Fa0/14 Altn BLK 19 128.16 P2p
Verify R1 can ping R2 via IPv6 and not IPv4:
R1#ping 192.168.12.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.2, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
R1#ping 2001::2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001::2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 0/1/4 ms
R1#
I used 0xAAAA because this what lsap type PVST uses. I don't know where I got this but I think I saw it on GS somehwere. I have also seen 0x4242 used but I think this is for normal STP (802.1d). In any case, only the 0xAAAA worked for me.
Tuesday, December 23, 2008
Monday, December 22, 2008
Extended Range VLAN - FAIL
I was reading an old post on CCIE talk about extended range vlans and I learned something new. The post is here: CCIE Talk
If a Catalyst switch has any routed ports then it uses an extended vlan as an "internal vlan" for that port. Why? I don't know but it's something to take caution with if you run into any issues.
Check it out:
SW1#sho vlan internal usage
VLAN Usage
---- --------------------
Now let's create a routed port:
SW1(config)#int f0/24
SW1(config-if)#no sw
Now we have VLAN 1006 taken up:
SW1#sho vlan internal usage
VLAN Usage
---- --------------------
1006 FastEthernet0/24
SW1#
What happens if we try to create or modify VLAN 1006? Let's see:
SW1(config)#vlan 1006
SW1(config-vlan)#exit
% Failed to create VLANs 1006
VLAN(s) not available in Port Manager.
%Failed to commit extended VLAN(s) changes.
00:06:13: %PM-4-EXT_VLAN_INUSE: VLAN 1006 currently in use by FastEthernet0/24
00:06:13: %SW_VLAN-4-VLAN_CREATE_FAIL: Failed to create VLANs 1006: VLAN(s) not available in Port Manager
SW1(config)#
FAIL. What if we were supposed to use VLAN 1006? Shut it down, enable VLAN 1006, then re-enable the port.
SW1(config)#int f0/24
SW1(config-if)#shut
SW1(config)#do show vlan internal usa
VLAN Usage
---- --------------------
SW1(config)#vlan 1006
SW1(config-vlan)#exit
SW1(config)#int f0/24
SW1(config-if)#no shut
SW1(config-if)#exit
SW1(config)#do show vlan internal usa
VLAN Usage
---- --------------------
1007 FastEthernet0/24
The switch uses the next number.
If a Catalyst switch has any routed ports then it uses an extended vlan as an "internal vlan" for that port. Why? I don't know but it's something to take caution with if you run into any issues.
Check it out:
SW1#sho vlan internal usage
VLAN Usage
---- --------------------
Now let's create a routed port:
SW1(config)#int f0/24
SW1(config-if)#no sw
Now we have VLAN 1006 taken up:
SW1#sho vlan internal usage
VLAN Usage
---- --------------------
1006 FastEthernet0/24
SW1#
What happens if we try to create or modify VLAN 1006? Let's see:
SW1(config)#vlan 1006
SW1(config-vlan)#exit
% Failed to create VLANs 1006
VLAN(s) not available in Port Manager.
%Failed to commit extended VLAN(s) changes.
00:06:13: %PM-4-EXT_VLAN_INUSE: VLAN 1006 currently in use by FastEthernet0/24
00:06:13: %SW_VLAN-4-VLAN_CREATE_FAIL: Failed to create VLANs 1006: VLAN(s) not available in Port Manager
SW1(config)#
FAIL. What if we were supposed to use VLAN 1006? Shut it down, enable VLAN 1006, then re-enable the port.
SW1(config)#int f0/24
SW1(config-if)#shut
SW1(config)#do show vlan internal usa
VLAN Usage
---- --------------------
SW1(config)#vlan 1006
SW1(config-vlan)#exit
SW1(config)#int f0/24
SW1(config-if)#no shut
SW1(config-if)#exit
SW1(config)#do show vlan internal usa
VLAN Usage
---- --------------------
1007 FastEthernet0/24
The switch uses the next number.
Friday, December 19, 2008
IP Source Guard
I was reading through the 3560 Configuration guide looking for things to lab and I came up with this. I already had DHCP snooping configured from my last lab so it was real easy.
Topology:
R1---SW1---R3
R1 has an address via DHCP:
R1#show ip int brief | ex unas
Ethernet0/0 192.168.12.1 YES DHCP up up
R1 can ping R3 on it's subnet:
R1#ping 192.168.12.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.3, timeout is 2 seconds:
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/3/4 ms
Sw1 has dhcp snooping already enabled. Here we configure IP source guard:
SW1(config)#int f0/1
SW1(config-if)#ip verify source
Now on R1 if we change the IP address, we cannot ping anymore:
R1(config)#int e0/0
R1(config-if)#ip address 192.168.12.100 255.255.255.0
R1(config-if)#^Z
R1#ping 192.168.12.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.3, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
Verify IP source guard is in effect on SW1:
SW1#show ip verify source
Interface Filter-type Filter-mode IP-address Mac-address Vlan
--------- ----------- ----------- --------------- -----------------
Fa0/1 ip active deny-all 12
Set R1 to get address via DHCP:
R1(config)#int e0/0
R1(config-if)#ip address dhcp
*Mar 1 02:53:06.259: %DHCP-6-ADDRESS_ASSIGN: Interface Ethernet0/0 assigned DHCP address 192.168.12.4, mask 255.255.255.0, hostname R1
Now R1 can ping again:
R1#ping 192.168.12.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.3, timeout is 2 seconds:
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/3/4 ms
Verify on SW1:
SW1#show ip verify source
Interface Filter-type Filter-mode IP-address Mac-address Vlan
--------- ----------- ----------- --------------- -----------------
Fa0/1 ip active 192.168.12.4 12
You can also configure static bindings, but I will probably do that in another blog :)
Topology:
R1---SW1---R3
R1 has an address via DHCP:
R1#show ip int brief | ex unas
Ethernet0/0 192.168.12.1 YES DHCP up up
R1 can ping R3 on it's subnet:
R1#ping 192.168.12.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.3, timeout is 2 seconds:
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/3/4 ms
Sw1 has dhcp snooping already enabled. Here we configure IP source guard:
SW1(config)#int f0/1
SW1(config-if)#ip verify source
Now on R1 if we change the IP address, we cannot ping anymore:
R1(config)#int e0/0
R1(config-if)#ip address 192.168.12.100 255.255.255.0
R1(config-if)#^Z
R1#ping 192.168.12.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.3, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
Verify IP source guard is in effect on SW1:
SW1#show ip verify source
Interface Filter-type Filter-mode IP-address Mac-address Vlan
--------- ----------- ----------- --------------- -----------------
Fa0/1 ip active deny-all 12
Set R1 to get address via DHCP:
R1(config)#int e0/0
R1(config-if)#ip address dhcp
*Mar 1 02:53:06.259: %DHCP-6-ADDRESS_ASSIGN: Interface Ethernet0/0 assigned DHCP address 192.168.12.4, mask 255.255.255.0, hostname R1
Now R1 can ping again:
R1#ping 192.168.12.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.12.3, timeout is 2 seconds:
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/3/4 ms
Verify on SW1:
SW1#show ip verify source
Interface Filter-type Filter-mode IP-address Mac-address Vlan
--------- ----------- ----------- --------------- -----------------
Fa0/1 ip active 192.168.12.4 12
You can also configure static bindings, but I will probably do that in another blog :)
Wednesday, December 17, 2008
SLA - Sending a Constant Bitrate
Everytime I study QoS I think about ways to generate a constant rate of traffic from a router. I always test using pings but I never really know at what rate data is being pushed through. With SLA, I can configure a somewhat rudimentary way of doing this.
Suppose I want a router R1 to send 64K to R7 (off in the distance).
Let's figure out the data size and frequency. There are probably multiple ways to do this depending on frequency and request-data-size but here is how I do it:
My load-interval on R7 is going to be 30 seconds so 1,920,000 (64,000 x 30) bits need to flow through every 30 second interval. Now if I send data a 1 second intervals, then I need to send 64000 bits every second. 64000 bits = 8000 bytes.
Formula using 1 second frequency intervals:
Load-interval X desired bitrate = total bits per interval
total bits per interval / 8 = request-data-size
Here is the config:
R1(config)#ip sla monitor 1
R1(config-sla-monitor)#type echo protocol ipIcmpEcho 150.100.56.7
R1(config-sla-monitor-echo)#request-data-size 8000
R1(config-sla-monitor-echo)#frequency 1
On R7 I created this tracker:
ip sla monitor responder
access-list 100 permit icmp host 150.100.12.1 any
class-map match-all SLA
match access-group 100
policy-map TRACK-SLA
class SLA
interface FastEthernet0/0
service-policy input TRACK-SLA
Now Let's start the SLA monitor on R1:
R1(config)#ip sla monitor schedule 1 life forever start-time now
Now on R7 we use the show policy-map interface command to see the bit rate. It takes a little while but it should peak near 64000 bps give or take 1000.
After 750 packets we have 65K:
R7#sho policy-map interface
FastEthernet0/0
Service-policy input: TRACK-SLA
Class-map: SLA (match-all)
750 packets, 1027500 bytes
30 second offered rate 65000 bps
Match: access-group 100
Class-map: class-default (match-any)
91 packets, 6548 bytes
30 second offered rate 0 bps, drop rate 0 bps
Match: any
Now several minutes later we are still at 65K:
R7#sho policy-map interface
FastEthernet0/0
Service-policy input: TRACK-SLA
Class-map: SLA (match-all)
2784 packets, 3814080 bytes
30 second offered rate 65000 bps
Match: access-group 100
Class-map: class-default (match-any)
280 packets, 20188 bytes
30 second offered rate 0 bps, drop rate 0 bps
Match: any
Suppose I want a router R1 to send 64K to R7 (off in the distance).
Let's figure out the data size and frequency. There are probably multiple ways to do this depending on frequency and request-data-size but here is how I do it:
My load-interval on R7 is going to be 30 seconds so 1,920,000 (64,000 x 30) bits need to flow through every 30 second interval. Now if I send data a 1 second intervals, then I need to send 64000 bits every second. 64000 bits = 8000 bytes.
Formula using 1 second frequency intervals:
Load-interval X desired bitrate = total bits per interval
total bits per interval / 8 = request-data-size
Here is the config:
R1(config)#ip sla monitor 1
R1(config-sla-monitor)#type echo protocol ipIcmpEcho 150.100.56.7
R1(config-sla-monitor-echo)#request-data-size 8000
R1(config-sla-monitor-echo)#frequency 1
On R7 I created this tracker:
ip sla monitor responder
access-list 100 permit icmp host 150.100.12.1 any
class-map match-all SLA
match access-group 100
policy-map TRACK-SLA
class SLA
interface FastEthernet0/0
service-policy input TRACK-SLA
Now Let's start the SLA monitor on R1:
R1(config)#ip sla monitor schedule 1 life forever start-time now
Now on R7 we use the show policy-map interface command to see the bit rate. It takes a little while but it should peak near 64000 bps give or take 1000.
After 750 packets we have 65K:
R7#sho policy-map interface
FastEthernet0/0
Service-policy input: TRACK-SLA
Class-map: SLA (match-all)
750 packets, 1027500 bytes
30 second offered rate 65000 bps
Match: access-group 100
Class-map: class-default (match-any)
91 packets, 6548 bytes
30 second offered rate 0 bps, drop rate 0 bps
Match: any
Now several minutes later we are still at 65K:
R7#sho policy-map interface
FastEthernet0/0
Service-policy input: TRACK-SLA
Class-map: SLA (match-all)
2784 packets, 3814080 bytes
30 second offered rate 65000 bps
Match: access-group 100
Class-map: class-default (match-any)
280 packets, 20188 bytes
30 second offered rate 0 bps, drop rate 0 bps
Match: any
Parser View
I was reading this pdf called "1001 things to do with a Cisco Router" and I came across this topic. I have done it before while doing the ISCW but here it is again.
FIRST, ENABLE AAA:
R4#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R4(config)#aaa new-model
SET ENABLE PASSWORD:
R4(config)#enable secret cisco
R4(config)#^Z
SWITCH TO VIEW MODE:
R4#en view
Password:
R4#
*Mar 2 23:03:20.352: %PARSER-6-VIEW_SWITCH: successfully set to view 'root'.
R4#
NOW WE CAN CREATE THE VIEW:
R4(config)#parser view operator
R4(config-view)#?
View commands:
commands Configure commands for a view
default Set a command to its defaults
exit Exit from view configuration mode
no Negate a command or set its defaults
secret Set a secret for the current view
R4(config-view)#commands exec include ping
% Password not set for the view operator
R4(config-view)#secret operator
R4(config-view)#commands exec include ping
R4(config-view)#commands exec include show hardware
R4(config-view)#commands exec include show interface
R4(config-view)#commands exec include show ver
R4(config-view)#exit
LOG IN TO THE VIEW:
R4#en view operator
Password:
*Mar 2 23:05:41.212: %PARSER-6-VIEW_SWITCH: successfully set to view 'operator'.
R4#show ?
flash: display information about flash: file system
hardware Hardware specific information
interfaces Interface status and configuration
parser Display parser information
slot0: display information about slot0: file system
slot1: display information about slot1: file system
version System hardware and software status
ALSO, YOU CAN ADD THE VIEW TO THE USER:
R4(config)#username operator view operator password operator
FIRST, ENABLE AAA:
R4#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R4(config)#aaa new-model
SET ENABLE PASSWORD:
R4(config)#enable secret cisco
R4(config)#^Z
SWITCH TO VIEW MODE:
R4#en view
Password:
R4#
*Mar 2 23:03:20.352: %PARSER-6-VIEW_SWITCH: successfully set to view 'root'.
R4#
NOW WE CAN CREATE THE VIEW:
R4(config)#parser view operator
R4(config-view)#?
View commands:
commands Configure commands for a view
default Set a command to its defaults
exit Exit from view configuration mode
no Negate a command or set its defaults
secret Set a secret for the current view
R4(config-view)#commands exec include ping
% Password not set for the view operator
R4(config-view)#secret operator
R4(config-view)#commands exec include ping
R4(config-view)#commands exec include show hardware
R4(config-view)#commands exec include show interface
R4(config-view)#commands exec include show ver
R4(config-view)#exit
LOG IN TO THE VIEW:
R4#en view operator
Password:
*Mar 2 23:05:41.212: %PARSER-6-VIEW_SWITCH: successfully set to view 'operator'.
R4#show ?
flash: display information about flash: file system
hardware Hardware specific information
interfaces Interface status and configuration
parser Display parser information
slot0: display information about slot0: file system
slot1: display information about slot1: file system
version System hardware and software status
ALSO, YOU CAN ADD THE VIEW TO THE USER:
R4(config)#username operator view operator password operator
Monday, December 15, 2008
DHCP Snooping - missing command?
I was having a hard time with this awhile ago because I could not get an address even when I enabled "trust" on the server port. However, after looking through the PG on Mock Lab 3 and discussion in the cisco channel on freenode I found out the issue.
I needed this command on the server:
R2(config)#int e0/0
R2(config-if)#ip dhcp relay information trusted
Now my binding database is populated after about 9 months!
SW1#show ip dhcp snooping binding
MacAddress IpAddress Lease(sec) Type VLAN Interface
------------------ --------------- ---------- ------------- ---- --------------------
00:07:EB:14:4F:81 192.168.12.1 86312 dhcp-snooping 12 FastEthernet0/1
Total number of bindings: 1
SW1#
I needed this command on the server:
R2(config)#int e0/0
R2(config-if)#ip dhcp relay information trusted
Now my binding database is populated after about 9 months!
SW1#show ip dhcp snooping binding
MacAddress IpAddress Lease(sec) Type VLAN Interface
------------------ --------------- ---------- ------------- ---- --------------------
00:07:EB:14:4F:81 192.168.12.1 86312 dhcp-snooping 12 FastEthernet0/1
Total number of bindings: 1
SW1#
Sunday, December 14, 2008
IPexpert Volume 3 Mock Lab 3 Review
I finished this lab in a little more than 6 hours. It was a graded lab through Proctor Labs and I got an 82. This a very challenging lab because there was some dot1q tunneling involved and it affected reachability if you didn't prune VLANs properly due to l2portguard errors. Also, there was an IPv6 tunneling section which I got right. In fact, I got 100% on IGP, BGP and Multicast for a total of 44 points.
Here are the mistakes I made:
-3 1.2 Switching
Did not enable trust on the trunk ports after I enabled DHCP snhooping.
-2 2.3 Frame Relay
After I did some NAT R4 could no longer ping R2 over the Frame-relay.
-3 6.1 VRRP
I used group 1 instead of group 24. BONEHEAD mistake.
-4 6.5 IOS Services
Some NAT stuff. I think I got this right but...oh well.
-3 8.1 QoS
PBR config was supposedly on the wrong interface. I am arguing this one with the script writers.
-3 9.2 Security
I got the URL string wrong for blocking NIMDA.
All in all I felt pretty good. I had been practicing tunneling last night and I don't think I would have done as well or finished as fast if I hadn't. I gained a lot of confidence this round. There were some things I did not think I would be able to figure out upon the initial read-through. However, once I turned off the TV, I was in a pretty good groove :-)
Here are the mistakes I made:
-3 1.2 Switching
Did not enable trust on the trunk ports after I enabled DHCP snhooping.
-2 2.3 Frame Relay
After I did some NAT R4 could no longer ping R2 over the Frame-relay.
-3 6.1 VRRP
I used group 1 instead of group 24. BONEHEAD mistake.
-4 6.5 IOS Services
Some NAT stuff. I think I got this right but...oh well.
-3 8.1 QoS
PBR config was supposedly on the wrong interface. I am arguing this one with the script writers.
-3 9.2 Security
I got the URL string wrong for blocking NIMDA.
All in all I felt pretty good. I had been practicing tunneling last night and I don't think I would have done as well or finished as fast if I hadn't. I gained a lot of confidence this round. There were some things I did not think I would be able to figure out upon the initial read-through. However, once I turned off the TV, I was in a pretty good groove :-)
Saturday, December 13, 2008
IPexpert Volume 2 Section 13 Reveiw - Part II
I just finished the lab that I started last week. I don't really have an estimate of how well I did because I had several conflicts with the PG. My guess is around 70 - 80. It was definitely the hardest full scale practice lab I have done to date. Not so much in configuration, just in understanding what the PG was trying to say. Here are some examples:
R2 should show L2 circuit IDs when viewing "debug traces." This was in the security section and the answer was to create an ACL that permitted everything and log-input for ICMP. Easy enough and I thought about that solution but I thought there might have been another way - alas, there wasn't.
CAT1 should only allow PC with mac address 0001.0001.0001 and IP 10.10.10.1 on port f0/10. I thought about ARP inspection along with port security but the answer was only port security. Not sure if I would gotten it wrong if I had the port security right but borked on the ARP inspection which was not required.
There was also an auto-command task that forced me to override what I had already configured for my VTY lines in previous tasks. I would have had to ask the proctor about this as there was no way to have the two solutions (line password and local authentication) without AAA. And my AAA solution was not allowing auto-command to work.
There was a total of 58 tasks on this lab which is incredible because I don't think I have had a lab that had as many as 40 yet. Each task was 1 or 2 points and there was a lot to configure. I don't know if I would have completed it in 8 hours - I took my time writing emails to support during the lab.
In any case, this was a very challenging lab and I think I will re-do this one in a couple months if I have time.
R2 should show L2 circuit IDs when viewing "debug traces." This was in the security section and the answer was to create an ACL that permitted everything and log-input for ICMP. Easy enough and I thought about that solution but I thought there might have been another way - alas, there wasn't.
CAT1 should only allow PC with mac address 0001.0001.0001 and IP 10.10.10.1 on port f0/10. I thought about ARP inspection along with port security but the answer was only port security. Not sure if I would gotten it wrong if I had the port security right but borked on the ARP inspection which was not required.
There was also an auto-command task that forced me to override what I had already configured for my VTY lines in previous tasks. I would have had to ask the proctor about this as there was no way to have the two solutions (line password and local authentication) without AAA. And my AAA solution was not allowing auto-command to work.
There was a total of 58 tasks on this lab which is incredible because I don't think I have had a lab that had as many as 40 yet. Each task was 1 or 2 points and there was a lot to configure. I don't know if I would have completed it in 8 hours - I took my time writing emails to support during the lab.
In any case, this was a very challenging lab and I think I will re-do this one in a couple months if I have time.
Auto-install, eh?
While doing IPexpert Volume 2 Section 13 I ran into a task that said:
"There is a high chance you will be replacing your current R4 router with another high-end router. The admin of R4 has saved its configuration on a TFTP server whose IP address is 136.10.12.100. Make sure the new router will automatically configure itself."
So I started browsing through the DocCD for auto-install when it hit me...how exactly is this supposed to work? Not knowing the exact details about auto-install I knew that this should be a simple task since it was only 1 point.
Well the new router needs to know about address 136.10.12.100 somehow...but when it has no config it has no address. What I figured was that the new router will send a broadcast on it's frame-relay interface which happens to connect to R2. In fact the 136.10.12.100 network is also on R2's ethernet interface.
So I configured a helper address on R2's frame-relay interface pointing to 136.10.12.100. The PG agreed! 1 task, 1 command, 1 point :-)
"There is a high chance you will be replacing your current R4 router with another high-end router. The admin of R4 has saved its configuration on a TFTP server whose IP address is 136.10.12.100. Make sure the new router will automatically configure itself."
So I started browsing through the DocCD for auto-install when it hit me...how exactly is this supposed to work? Not knowing the exact details about auto-install I knew that this should be a simple task since it was only 1 point.
Well the new router needs to know about address 136.10.12.100 somehow...but when it has no config it has no address. What I figured was that the new router will send a broadcast on it's frame-relay interface which happens to connect to R2. In fact the 136.10.12.100 network is also on R2's ethernet interface.
So I configured a helper address on R2's frame-relay interface pointing to 136.10.12.100. The PG agreed! 1 task, 1 command, 1 point :-)
Thursday, December 11, 2008
ECMP Multicast Load Splitting
This is a pretty simple concept. By default when two paths to the RP exist, the router sends a join to the one with the highest IP address. When you enable multicast multipath, the router will send joins up multiple paths depending on Source address (this hash is modifiable in some IOS)
Here is the topology:

R4 has joined group 239.0.0.1. R5, R6 and R7 are all sending pings to this address. Before enabling multipath, this is what R1's mroute table looks like (it's actually bigger I am omitting output for the sake of brevity):
R1#show ip mroute | be \(
(*, 239.0.0.1), 00:00:09/stopped, RP 2.2.2.2, flags: SJC
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:09/00:02:50
(6.6.6.6, 239.0.0.1), 00:00:07/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:07/00:02:52
(150.100.56.5, 239.0.0.1), 00:00:05/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:05/00:02:54
(150.100.56.6, 239.0.0.1), 00:00:07/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:07/00:02:52
(150.100.56.7, 239.0.0.1), 00:00:10/00:02:57, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:10/00:02:49
Notice that it has sent joins only on Serial 1/3. Thus, R2 only sends multicast traffic for 239.0.0.1 out of this interface. R2 OIL looks like this:
R2#show ip mroute 239.0.0.1 | sec Outgoing
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:34:58/00:02:44
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:13:39/00:02:44
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:13:39/00:02:46
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:13:39/00:02:45
Let's enable multicast multipath on R1:
R1(config)#ip multicast multipath
Now we can see Joins have been sent out of both interfaces:
R1#show ip mroute | be \(
(*, 239.0.0.1), 00:00:01/stopped, RP 2.2.2.2, flags: SJC
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(6.6.6.6, 239.0.0.1), 00:00:01/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(150.100.56.5, 239.0.0.1), 00:00:01/00:02:58, flags: J
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(150.100.56.6, 239.0.0.1), 00:00:01/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(150.100.56.7, 239.0.0.1), 00:00:00/00:02:59, flags: J
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:00/00:02:59
R2's OIL now looks like this:
R2#show ip mroute 239.0.0.1 | section Outg
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:03:03/00:03:26
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:01:31/00:03:26
Outgoing interface list:
Serial1/2, Forward/Sparse, 00:01:02/00:03:25
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:01:31/00:03:26
At first I wasn't sure if hashing is done on source or source/group, but I found out by sending to different groups from the same address to see if it splits up. From what I can tell it uses the source to hash, so one source sending to multiple groups will not get split.
R1#show ip mroute | be \(
(150.100.100.5, 238.0.0.1), 00:00:04/00:02:55, flags: JT
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:04/00:02:55
(150.100.100.5, 239.0.0.2), 00:00:49/00:02:17, flags: JT
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:49/00:02:56
(150.100.100.5, 239.0.0.3), 00:00:45/00:02:17, flags: JT
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:50/00:02:50
There is another train of IOS where you can select what to hash on, but my IOS doesn't have it.
Key thing to remember:
-Enabling multipath causes Joins to get sent towards the RP on more than one interface. This is what causes the load-splitting. Careful not to confuse this with the downstream sending of traffic, by default the router will send it out all interfaces (in the OIL) anyway!
Here is the topology:

R4 has joined group 239.0.0.1. R5, R6 and R7 are all sending pings to this address. Before enabling multipath, this is what R1's mroute table looks like (it's actually bigger I am omitting output for the sake of brevity):
R1#show ip mroute | be \(
(*, 239.0.0.1), 00:00:09/stopped, RP 2.2.2.2, flags: SJC
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:09/00:02:50
(6.6.6.6, 239.0.0.1), 00:00:07/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:07/00:02:52
(150.100.56.5, 239.0.0.1), 00:00:05/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:05/00:02:54
(150.100.56.6, 239.0.0.1), 00:00:07/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:07/00:02:52
(150.100.56.7, 239.0.0.1), 00:00:10/00:02:57, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:10/00:02:49
Notice that it has sent joins only on Serial 1/3. Thus, R2 only sends multicast traffic for 239.0.0.1 out of this interface. R2 OIL looks like this:
R2#show ip mroute 239.0.0.1 | sec Outgoing
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:34:58/00:02:44
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:13:39/00:02:44
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:13:39/00:02:46
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:13:39/00:02:45
Let's enable multicast multipath on R1:
R1(config)#ip multicast multipath
Now we can see Joins have been sent out of both interfaces:
R1#show ip mroute | be \(
(*, 239.0.0.1), 00:00:01/stopped, RP 2.2.2.2, flags: SJC
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(6.6.6.6, 239.0.0.1), 00:00:01/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(150.100.56.5, 239.0.0.1), 00:00:01/00:02:58, flags: J
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(150.100.56.6, 239.0.0.1), 00:00:01/00:02:58, flags: JT
Incoming interface: Serial1/3, RPF nbr 150.100.21.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:01/00:02:58
(150.100.56.7, 239.0.0.1), 00:00:00/00:02:59, flags: J
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:00/00:02:59
R2's OIL now looks like this:
R2#show ip mroute 239.0.0.1 | section Outg
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:03:03/00:03:26
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:01:31/00:03:26
Outgoing interface list:
Serial1/2, Forward/Sparse, 00:01:02/00:03:25
Outgoing interface list:
Serial1/3, Forward/Sparse, 00:01:31/00:03:26
At first I wasn't sure if hashing is done on source or source/group, but I found out by sending to different groups from the same address to see if it splits up. From what I can tell it uses the source to hash, so one source sending to multiple groups will not get split.
R1#show ip mroute | be \(
(150.100.100.5, 238.0.0.1), 00:00:04/00:02:55, flags: JT
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:04/00:02:55
(150.100.100.5, 239.0.0.2), 00:00:49/00:02:17, flags: JT
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:49/00:02:56
(150.100.100.5, 239.0.0.3), 00:00:45/00:02:17, flags: JT
Incoming interface: Serial1/2, RPF nbr 150.100.12.2
Outgoing interface list:
FastEthernet0/0, Forward/Sparse, 00:00:50/00:02:50
There is another train of IOS where you can select what to hash on, but my IOS doesn't have it.
Key thing to remember:
-Enabling multipath causes Joins to get sent towards the RP on more than one interface. This is what causes the load-splitting. Careful not to confuse this with the downstream sending of traffic, by default the router will send it out all interfaces (in the OIL) anyway!
Wednesday, December 10, 2008
IPv6 Tunneling - ISATAP
R2, R5 and R6 connected via an IPv4 frame-relay network.
There is no PVC in use between R5 and R6.
Each device has a loopback 192.168.x.x where x is router number.
The goal here is to allow the remote IPv6 networks to communicate over the IPv4 cloud.

Below are the configs.
Loopback 100 = tunnel endpoint
Loopback 101 = "remote" network
R6:
interface Loopback100
ip address 192.168.6.6 255.255.255.255
interface Loopback101
no ip address
ipv6 address 2001:600::6/64
interface Tunnel1
ipv6 address 2001:200::/64 eui-64
tunnel source Loopback100
tunnel mode ipv6ip isatap
R5:
interface Loopback100
ip address 192.168.5.5 255.255.255.255
interface Loopback101
no ip address
ipv6 address 2001:500::5/64
interface Tunnel1
ipv6 address 2001:200::/64 eui-64
tunnel source Loopback100
tunnel mode ipv6ip isatap
Static routes on R5 and R6:
R5(config)#ipv6 route 2001:600::/64 tunnel 1 fe80::5efe:c0a8:0606
R6(config)#ipv6 route 2001:500::/64 tunnel 1 fe80::5efe:c0a8:0505
Where did I get these next hops? Well when you create an ISATAP tunnel they are created in a modified eui-64 format. Take a look
at R5:
R5#show ipv6 interface brief tun 1
Tunnel1 [up/up]
FE80::5EFE:C0A8:505
2001:200::5EFE:C0A8:505
When the router decides to route a packet out of that tunnel interface, it calculates the Ipv4 next hop address from the last 32 bits of the modified eui-64 address. In this case C0A8:505 converts to 192.168.5.5. R6 sends all packets destined for 2001:500::/64 to 192.168.5.5.
Key things to remember:
-The tunnel source address must be reachable by remote routers
-There is no manually specified tunnel destination
-You must specify the tunnel interface and link layer address in static routes
There is no PVC in use between R5 and R6.
Each device has a loopback 192.168.x.x where x is router number.
The goal here is to allow the remote IPv6 networks to communicate over the IPv4 cloud.

Below are the configs.
Loopback 100 = tunnel endpoint
Loopback 101 = "remote" network
R6:
interface Loopback100
ip address 192.168.6.6 255.255.255.255
interface Loopback101
no ip address
ipv6 address 2001:600::6/64
interface Tunnel1
ipv6 address 2001:200::/64 eui-64
tunnel source Loopback100
tunnel mode ipv6ip isatap
R5:
interface Loopback100
ip address 192.168.5.5 255.255.255.255
interface Loopback101
no ip address
ipv6 address 2001:500::5/64
interface Tunnel1
ipv6 address 2001:200::/64 eui-64
tunnel source Loopback100
tunnel mode ipv6ip isatap
Static routes on R5 and R6:
R5(config)#ipv6 route 2001:600::/64 tunnel 1 fe80::5efe:c0a8:0606
R6(config)#ipv6 route 2001:500::/64 tunnel 1 fe80::5efe:c0a8:0505
Where did I get these next hops? Well when you create an ISATAP tunnel they are created in a modified eui-64 format. Take a look
at R5:
R5#show ipv6 interface brief tun 1
Tunnel1 [up/up]
FE80::5EFE:C0A8:505
2001:200::5EFE:C0A8:505
When the router decides to route a packet out of that tunnel interface, it calculates the Ipv4 next hop address from the last 32 bits of the modified eui-64 address. In this case C0A8:505 converts to 192.168.5.5. R6 sends all packets destined for 2001:500::/64 to 192.168.5.5.
Key things to remember:
-The tunnel source address must be reachable by remote routers
-There is no manually specified tunnel destination
-You must specify the tunnel interface and link layer address in static routes
Multicast - IGMP Profile
Here is the topology for this lab:
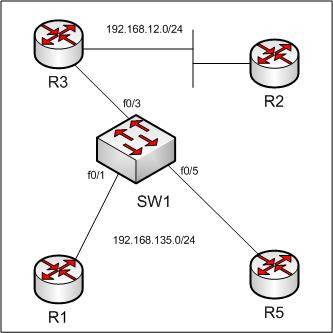
R2 is the RP and will be sending multicast pings.
R3 is the PIM DR for the 192.168.135.0 segment.
We will prevent R5 from joining group 239.0.0.1.
To deny IGMP joins on a switch, we use the IGMP filter and profile commands.
First, create the profile:
SW1(config)#ip igmp profile 1
SW1(config-igmp-profile)#deny
SW1(config-igmp-profile)#range 239.0.0.1 239.0.0.5
SW1(config-igmp-profile)#exit
Then attach it to the port:
SW1(config)#int f0/5
SW1(config-if)#ip igmp filter 1
Now we can test by having R1 and R5 join a group in the range 239.0.0.1 - 239.0.0.5
R1(config)#int e0/0
R1(config-if)#ip igmp join-group 239.0.0.1
R5(config)#int e0/0
R5(config-if)#ip igmp join-group 239.0.0.1
Let's debug on SW1 and see what happens:
SW1#debug ip igmp filter
event debugging is on
SW1#
03:26:30: IGMPFILTER: igmp_filter_process_pkt(): checking group 239.0.0.1 from Fa0/5: deny
03:26:31: IGMPFILTER: igmp_filter_process_pkt() checking group from Fa0/3 : no profile attached
03:26:33: IGMPFILTER: igmp_filter_process_pkt() checking group from Fa0/1 : no profile attached
No let's check R3 for any joined groups:
R3#show ip igmp groups
IGMP Connected Group Membership
Group Address Interface Uptime Expires Last Reporter
239.0.0.1 Ethernet0/0 00:09:28 00:02:30 192.168.135.1
224.0.1.40 Ethernet0/1 00:29:57 00:02:09 192.168.23.2
224.0.1.40 Ethernet0/0 00:30:01 00:02:37 192.168.135.3
Just to make sure, we can verify that only R1 responds to pings:
R2#ping 239.0.0.1
Type escape sequence to abort.
Sending 1, 100-byte ICMP Echos to 239.0.0.1, timeout is 2 seconds:
Reply to request 0 from 192.168.135.1, 8 ms
R2#

R2 is the RP and will be sending multicast pings.
R3 is the PIM DR for the 192.168.135.0 segment.
We will prevent R5 from joining group 239.0.0.1.
To deny IGMP joins on a switch, we use the IGMP filter and profile commands.
First, create the profile:
SW1(config)#ip igmp profile 1
SW1(config-igmp-profile)#deny
SW1(config-igmp-profile)#range 239.0.0.1 239.0.0.5
SW1(config-igmp-profile)#exit
Then attach it to the port:
SW1(config)#int f0/5
SW1(config-if)#ip igmp filter 1
Now we can test by having R1 and R5 join a group in the range 239.0.0.1 - 239.0.0.5
R1(config)#int e0/0
R1(config-if)#ip igmp join-group 239.0.0.1
R5(config)#int e0/0
R5(config-if)#ip igmp join-group 239.0.0.1
Let's debug on SW1 and see what happens:
SW1#debug ip igmp filter
event debugging is on
SW1#
03:26:30: IGMPFILTER: igmp_filter_process_pkt(): checking group 239.0.0.1 from Fa0/5: deny
03:26:31: IGMPFILTER: igmp_filter_process_pkt() checking group from Fa0/3 : no profile attached
03:26:33: IGMPFILTER: igmp_filter_process_pkt() checking group from Fa0/1 : no profile attached
No let's check R3 for any joined groups:
R3#show ip igmp groups
IGMP Connected Group Membership
Group Address Interface Uptime Expires Last Reporter
239.0.0.1 Ethernet0/0 00:09:28 00:02:30 192.168.135.1
224.0.1.40 Ethernet0/1 00:29:57 00:02:09 192.168.23.2
224.0.1.40 Ethernet0/0 00:30:01 00:02:37 192.168.135.3
Just to make sure, we can verify that only R1 responds to pings:
R2#ping 239.0.0.1
Type escape sequence to abort.
Sending 1, 100-byte ICMP Echos to 239.0.0.1, timeout is 2 seconds:
Reply to request 0 from 192.168.135.1, 8 ms
R2#
Tuesday, December 9, 2008
L2protocol Tunneling - An STP Example
This is a short lab designed to help me get familiar with l2protocol tunneling, specifically tunneling STP. We are also going tunnel CDP and VTP. What's neat about this is that we will alter the STP topology without using priority or changing mac addresses. Also, SW1 will see two switches as CDP neighbors on one port.
Here is the topolgy:

Currently SW4 is root with SW2 is blocking f0/16. This works best with SW4 or SW3 as root.
SW2# show spanning-tree blockedports
Name Blocked Interfaces List
-------------------- ------------------------------------
VLAN0001 Fa0/16
Number of blocked ports (segments) in the system : 1
We can use l2protocol tunneling to create a logical loop between SW1, SW3 and SW4 and force the link between SW3 and SW4 to block. Logically that would look like this:

Physically we would have this, with SW2 not being a part of the VTP domain, any CDP relationship or STP topology:

This might be a practical case where SW2 was a service provider switch/cloud. SW1, SW3, and SW4 would then be remote switches with SW3 and SW4 having a backdoor connection.
Now for the configuration. SW1, SW3 and SW4 configure their links as trunks:
SW1(config)#int f0/13
SW1(config-if)#sw t e d
SW1(config-if)#sw mo t
SW1(config-if)#no shut
Repeat this on ports f0/16 and f0/19 of SW3 and SW4. SW2 has the following configuration:
SW2(config-if)#int rang f0/13, f0/16, f0/19
SW2(config-if-range)#swit mode dot1q-tunnel
SW2(config-if-range)#l2protocol-tunnel cdp
SW2(config-if-range)#l2protocol-tunnel stp
SW2(config-if-range)#l2protocol-tunnel vtp
Now let's verify some things. First, we can see SW3 and SW4 as CDP neighbors to SW1:
SW1#show cdp ne | be De
Device ID Local Intrfce Holdtme Capability Platform Port ID
SW4 Fas 0/13 156 S I WS-C3550-2Fas 0/16
SW3 Fas 0/13 158 S I WS-C3550-2Fas 0/16
R1 Fas 0/1 129 R S I 3640 Eth 0/0
SW1#
Notice they are both on interface f0/13. Now let's see who's blocking between SW3 or SW4:
SW3# show spanning-tree blockedports | be VLAN
VLAN0001 Fa0/19
Number of blocked ports (segments) in the system : 1
SW3#
SW3 is blocking the connection between SW4. Perfect, just what we wanted.
This lab is designed as a little confidence booster. L2protocol tunneling is one of my weaknesses. I think because I recognize how complex it can get and it makes me worry (Ever since doing IPexpert V10 Volume 1 Lab 5). Practicing labs like this can help build confidence and gain familiarity with the configurations as well.
Here is the topolgy:

SW2# show spanning-tree blockedports
Name Blocked Interfaces List
-------------------- ------------------------------------
VLAN0001 Fa0/16
Number of blocked ports (segments) in the system : 1
We can use l2protocol tunneling to create a logical loop between SW1, SW3 and SW4 and force the link between SW3 and SW4 to block. Logically that would look like this:


Now for the configuration. SW1, SW3 and SW4 configure their links as trunks:
SW1(config)#int f0/13
SW1(config-if)#sw t e d
SW1(config-if)#sw mo t
SW1(config-if)#no shut
Repeat this on ports f0/16 and f0/19 of SW3 and SW4. SW2 has the following configuration:
SW2(config-if)#int rang f0/13, f0/16, f0/19
SW2(config-if-range)#swit mode dot1q-tunnel
SW2(config-if-range)#l2protocol-tunnel cdp
SW2(config-if-range)#l2protocol-tunnel stp
SW2(config-if-range)#l2protocol-tunnel vtp
Now let's verify some things. First, we can see SW3 and SW4 as CDP neighbors to SW1:
SW1#show cdp ne | be De
Device ID Local Intrfce Holdtme Capability Platform Port ID
SW4 Fas 0/13 156 S I WS-C3550-2Fas 0/16
SW3 Fas 0/13 158 S I WS-C3550-2Fas 0/16
R1 Fas 0/1 129 R S I 3640 Eth 0/0
SW1#
Notice they are both on interface f0/13.
SW3# show spanning-tree blockedports | be VLAN
VLAN0001 Fa0/19
Number of blocked ports (segments) in the system : 1
SW3#
SW3 is blocking the connection between SW4. Perfect, just what we wanted.
This lab is designed as a little confidence booster. L2protocol tunneling is one of my weaknesses. I think because I recognize how complex it can get and it makes me worry (Ever since doing IPexpert V10 Volume 1 Lab 5). Practicing labs like this can help build confidence and gain familiarity with the configurations as well.
Multicast Heartbeat - Generating SNMP Traps
This was a topic I ran into while browsing the multicast configuration guide today. I had dynamips up and running so I created a small lab.
Topology:
R1---R2---R5---R7
R1 is sending traffic to 225.0.0.7
R2 is the BSR/RP
R5 is will be configured for hearbeat
R7 has "ip igmp join-group 225.0.0.7" on one of its interfaces.
The commands to enable multicast heartbeat are very simple:
R5(config)#snmp-server host 9.9.9.9 traps public ipmulticast
R5(config)#snmp-server enable traps ipmulticast
R5(config)#ip multicast heartbeat 225.0.0.7 ?
<1-100> Minimal number of intervals where the heartbeats must be seen
R5(config)#ip multicast heartbeat 225.0.0.7 1 ?
<1-100> Number of intervals to monitor for heartbeat
R5(config)#ip multicast heartbeat 225.0.0.7 1 2 ?
<10-3600> Length of intervals in seconds
R5(config)#ip multicast heartbeat 225.0.0.7 1 2 10
R5(config)#
You will see this message:
R5#
*Mar 1 00:29:58.523: MHBEAT(0): Unless packets sent to 225.0.0.7 are seen in 1 out of 2 intervals of 10 seconds, an SNMP trap may be emitted.
Let's debug SNMP packets and the heartbeat so we can see the trap:
R5#debug snmp packets
SNMP packet debugging is on
R5#debug ip mhbeat
IP multicast heartbeat debugging is on
Now on R1 start sending packets, then stop:
R1#ping 225.0.0.7 re 2
Type escape sequence to abort.
Sending 10, 100-byte ICMP Echos to 225.0.0.7, timeout is 2 seconds:
Reply to request 0 from 150.100.56.7, 160 ms
Reply to request 1 from 150.100.56.7, 148 ms
R1#
Let's check R5. After a short while we see the following:
*Mar 1 00:38:48.555: MHBEAT(0): SNMP Trap for missing heartbeat
*Mar 1 00:38:48.575: SNMP: Queuing packet to 9.9.9.9
*Mar 1 00:38:48.575: SNMP: V1 Trap, ent ciscoExperiment.2.3.1, addr 150.100.56.5, gentrap 6, spectrap 1
ciscoIpMRouteHeartBeatEntry.2.225.0.0.7 = 0.0.0.0
ciscoIpMRouteHeartBeatEntry.3.225.0.0.7 = 10
ciscoIpMRouteHeartBeatEntry.4.225.0.0.7 = 2
ciscoIpMRouteHeartBeatEntry.5.225.0.0.7 = 0
*Mar 1 00:38:48.827: SNMP: Packet sent via UDP to 9.9.9.9
For reference, here is the link to the DocCD:
IP Multicast Heartbeat
Topology:
R1---R2---R5---R7
R1 is sending traffic to 225.0.0.7
R2 is the BSR/RP
R5 is will be configured for hearbeat
R7 has "ip igmp join-group 225.0.0.7" on one of its interfaces.
The commands to enable multicast heartbeat are very simple:
R5(config)#snmp-server host 9.9.9.9 traps public ipmulticast
R5(config)#snmp-server enable traps ipmulticast
R5(config)#ip multicast heartbeat 225.0.0.7 ?
<1-100> Minimal number of intervals where the heartbeats must be seen
R5(config)#ip multicast heartbeat 225.0.0.7 1 ?
<1-100> Number of intervals to monitor for heartbeat
R5(config)#ip multicast heartbeat 225.0.0.7 1 2 ?
<10-3600> Length of intervals in seconds
R5(config)#ip multicast heartbeat 225.0.0.7 1 2 10
R5(config)#
You will see this message:
R5#
*Mar 1 00:29:58.523: MHBEAT(0): Unless packets sent to 225.0.0.7 are seen in 1 out of 2 intervals of 10 seconds, an SNMP trap may be emitted.
Let's debug SNMP packets and the heartbeat so we can see the trap:
R5#debug snmp packets
SNMP packet debugging is on
R5#debug ip mhbeat
IP multicast heartbeat debugging is on
Now on R1 start sending packets, then stop:
R1#ping 225.0.0.7 re 2
Type escape sequence to abort.
Sending 10, 100-byte ICMP Echos to 225.0.0.7, timeout is 2 seconds:
Reply to request 0 from 150.100.56.7, 160 ms
Reply to request 1 from 150.100.56.7, 148 ms
R1#
Let's check R5. After a short while we see the following:
*Mar 1 00:38:48.555: MHBEAT(0): SNMP Trap for missing heartbeat
*Mar 1 00:38:48.575: SNMP: Queuing packet to 9.9.9.9
*Mar 1 00:38:48.575: SNMP: V1 Trap, ent ciscoExperiment.2.3.1, addr 150.100.56.5, gentrap 6, spectrap 1
ciscoIpMRouteHeartBeatEntry.2.225.0.0.7 = 0.0.0.0
ciscoIpMRouteHeartBeatEntry.3.225.0.0.7 = 10
ciscoIpMRouteHeartBeatEntry.4.225.0.0.7 = 2
ciscoIpMRouteHeartBeatEntry.5.225.0.0.7 = 0
*Mar 1 00:38:48.827: SNMP: Packet sent via UDP to 9.9.9.9
For reference, here is the link to the DocCD:
IP Multicast Heartbeat
Monday, December 8, 2008
PPP - Negotiated address via DHCP
This kind of task may seem more difficult than it really is. I, in fact, spent way too long one morning/afternoon/evening trying to get this scenario to work. Turns out my server did not have a route back to the requester's subnet. So here it is without all the crap (ok, some of it) I went through:
Topology:
R5---R2---R1
R5 to R2 is PPP.
R5 needs to negotiate its address.
R1 is to supply this address.
R2-R5: 150.100.25.x/24
R1-R2: 150.100.12.x/24
R5 config is EASY:
interface Serial0/1
ip address negotiated
R2 is also easy, we configure it's interface to supply the address via DHCP and then specify a DHCP server:
R2(config)#int s1/1
R2(config-if)#peer default ip address dhcp
R2(config-if)#exit
R2(config)# ip dhcp-server 150.100.12.1
On R1 we configure the pool and everything is cool, right?
R1(config)#ip dhcp pool R5
R1(dhcp-config)#network 150.100.25.0 /24
R1(dhcp-config)#exit
R1(config)#ip dhcp excluded-address 150.100.25.1 150.100.25.4
R1(config)#ip dhcp excluded-address 150.100.25.6 150.100.25.255
Let's check R5, to see if it got an address:
R5#show ip int brief | inc l1/1
Serial1/1 unassigned YES IPCP up up
Nothing! Let's do some debugging on R1 with an ACL to match DHCP packets:
R1(config)#access-list 150 pe udp any any eq bootpc
R1(config)#access-list 150 pe udp any any eq bootps
R1(config)#access-list 150 pe udp any eq bootpc any
R1(config)#access-list 150 pe udp any eq bootps any
R1#debug ip packet 150 detail
IP packet debugging is on (detailed) for access list 150
*Mar 1 00:15:27.995: IP: s=150.100.12.1 (local), d=150.100.25.2, len 328, unroutable
*Mar 1 00:15:27.999: UDP src=67, dst=67
R1 has no route to 150.100.25.0/24 yet! Let's configure one and then manually shut/no shut the interface on R5:
R1(config)#ip route 150.100.25.0 255.255.255.0 150.100.12.2
R1#debug ip dhcp server events
*Mar 1 00:19:27.263: DHCPD: Sending notification of DISCOVER:
*Mar 1 00:19:27.263: DHCPD: htype 1 chaddr 0000.0c07.79e1
*Mar 1 00:19:27.267: DHCPD: circuit id 00000000
*Mar 1 00:19:27.267: DHCPD: Seeing if there is an internally specified pool class:
*Mar 1 00:19:27.271: DHCPD: htype 1 chaddr 0000.0c07.79e1
*Mar 1 00:19:27.271: DHCPD: circuit id 00000000
*Mar 1 00:19:28.411: DHCPD: Adding binding to radix tree (150.100.25.5)
*Mar 1 00:19:28.415: DHCPD: Adding binding to hash tree
*Mar 1 00:19:28.419: DHCPD: assigned IP address 150.100.25.5 to client 0063.6973.636f.2d31.3530.2e31.3030.2e32.352e.322d.5365.7269.616c.312f.31.
*Mar 1 00:19:28.495: DHCPD: Sending notification of ASSIGNMENT:
*Mar 1 00:19:28.499: DHCPD: address 150.100.25.5 mask 255.255.255.0
*Mar 1 00:19:28.499: DHCPD: htype 1 chaddr 0000.0c07.79e1
*Mar 1 00:19:28.503: DHCPD: lease time remaining (secs) = 86400
*Mar 1 00:20:17.647: DHCPD: checking for expired leases.
*Mar 1 00:22:17.647: DHCPD: checking for expired leases.
*Mar 1 00:24:17.647: DHCPD: checking for expired leases.
Now check R5:
R5#show ip int bri s1/1
Interface IP-Address OK? Method Status Protocol
Serial1/1 150.100.25.5 YES IPCP up up
R5#
*** IMPORTANT ***
R1 needs a route back to the 150.100.25.0/24 subnet. In this case I have a default route from R1 toward R2. This is EXTREMELY important. I wasted many minutes of my life trying to get this thing to come up. My DHCP configuration was correct but the DHCP server did not have a route back to the requester!
Topology:
R5---R2---R1
R5 to R2 is PPP.
R5 needs to negotiate its address.
R1 is to supply this address.
R2-R5: 150.100.25.x/24
R1-R2: 150.100.12.x/24
R5 config is EASY:
interface Serial0/1
ip address negotiated
R2 is also easy, we configure it's interface to supply the address via DHCP and then specify a DHCP server:
R2(config)#int s1/1
R2(config-if)#peer default ip address dhcp
R2(config-if)#exit
R2(config)# ip dhcp-server 150.100.12.1
On R1 we configure the pool and everything is cool, right?
R1(config)#ip dhcp pool R5
R1(dhcp-config)#network 150.100.25.0 /24
R1(dhcp-config)#exit
R1(config)#ip dhcp excluded-address 150.100.25.1 150.100.25.4
R1(config)#ip dhcp excluded-address 150.100.25.6 150.100.25.255
Let's check R5, to see if it got an address:
R5#show ip int brief | inc l1/1
Serial1/1 unassigned YES IPCP up up
Nothing! Let's do some debugging on R1 with an ACL to match DHCP packets:
R1(config)#access-list 150 pe udp any any eq bootpc
R1(config)#access-list 150 pe udp any any eq bootps
R1(config)#access-list 150 pe udp any eq bootpc any
R1(config)#access-list 150 pe udp any eq bootps any
R1#debug ip packet 150 detail
IP packet debugging is on (detailed) for access list 150
*Mar 1 00:15:27.995: IP: s=150.100.12.1 (local), d=150.100.25.2, len 328, unroutable
*Mar 1 00:15:27.999: UDP src=67, dst=67
R1 has no route to 150.100.25.0/24 yet! Let's configure one and then manually shut/no shut the interface on R5:
R1(config)#ip route 150.100.25.0 255.255.255.0 150.100.12.2
R1#debug ip dhcp server events
*Mar 1 00:19:27.263: DHCPD: Sending notification of DISCOVER:
*Mar 1 00:19:27.263: DHCPD: htype 1 chaddr 0000.0c07.79e1
*Mar 1 00:19:27.267: DHCPD: circuit id 00000000
*Mar 1 00:19:27.267: DHCPD: Seeing if there is an internally specified pool class:
*Mar 1 00:19:27.271: DHCPD: htype 1 chaddr 0000.0c07.79e1
*Mar 1 00:19:27.271: DHCPD: circuit id 00000000
*Mar 1 00:19:28.411: DHCPD: Adding binding to radix tree (150.100.25.5)
*Mar 1 00:19:28.415: DHCPD: Adding binding to hash tree
*Mar 1 00:19:28.419: DHCPD: assigned IP address 150.100.25.5 to client 0063.6973.636f.2d31.3530.2e31.3030.2e32.352e.322d.5365.7269.616c.312f.31.
*Mar 1 00:19:28.495: DHCPD: Sending notification of ASSIGNMENT:
*Mar 1 00:19:28.499: DHCPD: address 150.100.25.5 mask 255.255.255.0
*Mar 1 00:19:28.499: DHCPD: htype 1 chaddr 0000.0c07.79e1
*Mar 1 00:19:28.503: DHCPD: lease time remaining (secs) = 86400
*Mar 1 00:20:17.647: DHCPD: checking for expired leases.
*Mar 1 00:22:17.647: DHCPD: checking for expired leases.
*Mar 1 00:24:17.647: DHCPD: checking for expired leases.
Now check R5:
R5#show ip int bri s1/1
Interface IP-Address OK? Method Status Protocol
Serial1/1 150.100.25.5 YES IPCP up up
R5#
*** IMPORTANT ***
R1 needs a route back to the 150.100.25.0/24 subnet. In this case I have a default route from R1 toward R2. This is EXTREMELY important. I wasted many minutes of my life trying to get this thing to come up. My DHCP configuration was correct but the DHCP server did not have a route back to the requester!
Two vlans, One Port, No trunk
I recall a task somewhere I don't remember where we needed two vlans on one port but no trunk...in this case you can use a voice vlan for your second vlan. It is very easy to test:
Topology:
R1---SW1---SW2---R2
R1's interface:
interface Ethernet0/0
interface Ethernet0/0.2
encapsulation dot1Q 2
ip address 139.1.2.101 255.255.255.0
SW1:
interface FastEthernet0/1
switchport access vlan 11
switchport voice vlan 2
SW2:
SW2#show cdp ne | in R2
R2 Fas 0/2 135 R S I 3640 Eth 0/0
SW2#
Rack1SW2#show run int f0/2
Building configuration...
Current configuration : 83 bytes
!
interface FastEthernet0/2
switchport access vlan 2
switchport mode access
So let's ping from R1 to R2 (139.1.2.2)
Rack1R1#ping 139.1.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 139.1.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/4/4 ms
R1#
Topology:
R1---SW1---SW2---R2
R1's interface:
interface Ethernet0/0
interface Ethernet0/0.2
encapsulation dot1Q 2
ip address 139.1.2.101 255.255.255.0
SW1:
interface FastEthernet0/1
switchport access vlan 11
switchport voice vlan 2
SW2:
SW2#show cdp ne | in R2
R2 Fas 0/2 135 R S I 3640 Eth 0/0
SW2#
Rack1SW2#show run int f0/2
Building configuration...
Current configuration : 83 bytes
!
interface FastEthernet0/2
switchport access vlan 2
switchport mode access
So let's ping from R1 to R2 (139.1.2.2)
Rack1R1#ping 139.1.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 139.1.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/4/4 ms
R1#
IPv6 - Stateless autoconfig
Logical Topology:
R6------SW2
R6 is in vlan 6.
SW2 get its address for SVI 6 via stateless autoconfiguration.
R6 will be advertising the prefix for SW2 to use to build it's address.
R6 already has an IPv6 address configured: 2001:cc1e:1:6::6/64
Also, a good command to run here is "debug ipv6 nd".
Rack1R6#debug ipv6 nd
ICMP Neighbor Discovery events debugging is on
Rack1SW2#debug ipv6 nd
ICMP Neighbor Discovery events debugging is on
Before we do anything let's see what debugging gives us on R6:
Rack1R6#
*Mar 1 00:42:14.219: ICMPv6-ND: Sending RA to FF02::1 on Ethernet0/1
*Mar 1 00:42:14.219: ICMPv6-ND: MTU = 1500
*Mar 1 00:42:14.219: ICMPv6-ND: prefix = 2001:CC1E:1:6::/64 onlink autoconfig
*Mar 1 00:42:14.219: ICMPv6-ND: 2592000/604800 (valid/preferred)
Rack1R6#
We can see that R6 is already advertising it's prefix for hosts on this segment to use. Look at the output of the debug. We have
1) All nodes multicast address FF02::1, this is the destination of the RA advertisement
2) MTU of 1500
3) Prefix advertised by R6 2001:CC1E:1:6::/64
4) Valid and Preferred Lifetime 2592000/604800
All we need to do on SW2 is configure the SVI for autoconfiguration:
SW2#conf t
SW2(config)#int vlan 6
SW2(config-if)#ipv6 address ?
WORD General prefix name
X:X:X:X::X IPv6 link-local address
X:X:X:X::X/<0-128> IPv6 prefix
autoconfig Obtain address using autoconfiguration
SW2(config-if)#ipv6 address autoconfig
Notice that SW2 immediately sends an RS message asking for information about this segment:
00:19:39: ICMPv6-ND: Sending RS on Vlan6
00:19:39: ICMPv6-ND: Received RA from FE80::205:32FF:FE22:E442 on Vlan6
00:19:39: ICMPv6-ND: Sending NS for 2001:CC1E:1:6:21D:45FF:FEC0:F443 on Vlan6
00:19:39: ICMPv6-ND: Autoconfiguring 2001:CC1E:1:6:21D:45FF:FEC0:F443 on Vlan6
00:19:40: ICMPv6-ND: DAD: 2001:CC1E:1:6:21D:45FF:FEC0:F443 is unique.
00:19:40: ICMPv6-ND: Sending NA for 2001:CC1E:1:6:21D:45FF:FEC0:F443 on Vlan6
00:19:40: ICMPv6-ND: Address 2001:CC1E:1:6:21D:45FF:FEC0:F443/64 is up on Vlan6
It also receives the prefix, calcualtes its global unicast address and performs DAD. Now let's check the interface on SW2:
SW2#show ipv6 interface
Vlan6 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::21D:45FF:FEC0:F443
Global unicast address(es):
2001:CC1E:1:6:21D:45FF:FEC0:F443, subnet is 2001:CC1E:1:6::/64 [PRE]
valid lifetime 2591864 preferred lifetime 604664
Joined group address(es):
FF02::1
FF02::2
FF02::1:FFC0:F443
MTU is 1500 bytes
ICMP error messages limited to one every 100 milliseconds
ICMP redirects are enabled
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds
ND advertised reachable time is 0 milliseconds
ND advertised retransmit interval is 0 milliseconds
ND router advertisements are sent every 200 seconds
ND router advertisements live for 1800 seconds
ND advertised default router preference is Medium
Hosts use stateless autoconfig for addresses.
Rack1SW2#
There are several adjustments we can make on the timers. Let's look at R6:
R6(config-if)#ipv6 nd ?
advertisement-interval Send an advertisement interval option in RA's
dad Duplicate Address Detection
managed-config-flag Hosts should use DHCP for address config
ns-interval Set advertised NS retransmission interval
other-config-flag Hosts should use DHCP for non-address config
prefix Configure IPv6 Routing Prefix Advertisement
ra-interval Set IPv6 Router Advertisement Interval
ra-lifetime Set IPv6 Router Advertisement Lifetime
reachable-time Set advertised reachability time
suppress-ra Suppress IPv6 Router Advertisements
Here we can set various parameters such as the advertisement interval (200 seconds default) and the RA lifetime.
More information on these options can be found in the addressing section non the IPv6 configuration guide on the DocCD:
Implementing IPv6 Addressing and Basic Connectivity
R6------SW2
R6 is in vlan 6.
SW2 get its address for SVI 6 via stateless autoconfiguration.
R6 will be advertising the prefix for SW2 to use to build it's address.
R6 already has an IPv6 address configured: 2001:cc1e:1:6::6/64
Also, a good command to run here is "debug ipv6 nd".
Rack1R6#debug ipv6 nd
ICMP Neighbor Discovery events debugging is on
Rack1SW2#debug ipv6 nd
ICMP Neighbor Discovery events debugging is on
Before we do anything let's see what debugging gives us on R6:
Rack1R6#
*Mar 1 00:42:14.219: ICMPv6-ND: Sending RA to FF02::1 on Ethernet0/1
*Mar 1 00:42:14.219: ICMPv6-ND: MTU = 1500
*Mar 1 00:42:14.219: ICMPv6-ND: prefix = 2001:CC1E:1:6::/64 onlink autoconfig
*Mar 1 00:42:14.219: ICMPv6-ND: 2592000/604800 (valid/preferred)
Rack1R6#
We can see that R6 is already advertising it's prefix for hosts on this segment to use. Look at the output of the debug. We have
1) All nodes multicast address FF02::1, this is the destination of the RA advertisement
2) MTU of 1500
3) Prefix advertised by R6 2001:CC1E:1:6::/64
4) Valid and Preferred Lifetime 2592000/604800
All we need to do on SW2 is configure the SVI for autoconfiguration:
SW2#conf t
SW2(config)#int vlan 6
SW2(config-if)#ipv6 address ?
WORD General prefix name
X:X:X:X::X IPv6 link-local address
X:X:X:X::X/<0-128> IPv6 prefix
autoconfig Obtain address using autoconfiguration
SW2(config-if)#ipv6 address autoconfig
Notice that SW2 immediately sends an RS message asking for information about this segment:
00:19:39: ICMPv6-ND: Sending RS on Vlan6
00:19:39: ICMPv6-ND: Received RA from FE80::205:32FF:FE22:E442 on Vlan6
00:19:39: ICMPv6-ND: Sending NS for 2001:CC1E:1:6:21D:45FF:FEC0:F443 on Vlan6
00:19:39: ICMPv6-ND: Autoconfiguring 2001:CC1E:1:6:21D:45FF:FEC0:F443 on Vlan6
00:19:40: ICMPv6-ND: DAD: 2001:CC1E:1:6:21D:45FF:FEC0:F443 is unique.
00:19:40: ICMPv6-ND: Sending NA for 2001:CC1E:1:6:21D:45FF:FEC0:F443 on Vlan6
00:19:40: ICMPv6-ND: Address 2001:CC1E:1:6:21D:45FF:FEC0:F443/64 is up on Vlan6
It also receives the prefix, calcualtes its global unicast address and performs DAD. Now let's check the interface on SW2:
SW2#show ipv6 interface
Vlan6 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::21D:45FF:FEC0:F443
Global unicast address(es):
2001:CC1E:1:6:21D:45FF:FEC0:F443, subnet is 2001:CC1E:1:6::/64 [PRE]
valid lifetime 2591864 preferred lifetime 604664
Joined group address(es):
FF02::1
FF02::2
FF02::1:FFC0:F443
MTU is 1500 bytes
ICMP error messages limited to one every 100 milliseconds
ICMP redirects are enabled
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds
ND advertised reachable time is 0 milliseconds
ND advertised retransmit interval is 0 milliseconds
ND router advertisements are sent every 200 seconds
ND router advertisements live for 1800 seconds
ND advertised default router preference is Medium
Hosts use stateless autoconfig for addresses.
Rack1SW2#
There are several adjustments we can make on the timers. Let's look at R6:
R6(config-if)#ipv6 nd ?
advertisement-interval Send an advertisement interval option in RA's
dad Duplicate Address Detection
managed-config-flag Hosts should use DHCP for address config
ns-interval Set advertised NS retransmission interval
other-config-flag Hosts should use DHCP for non-address config
prefix Configure IPv6 Routing Prefix Advertisement
ra-interval Set IPv6 Router Advertisement Interval
ra-lifetime Set IPv6 Router Advertisement Lifetime
reachable-time Set advertised reachability time
suppress-ra Suppress IPv6 Router Advertisements
Here we can set various parameters such as the advertisement interval (200 seconds default) and the RA lifetime.
More information on these options can be found in the addressing section non the IPv6 configuration guide on the DocCD:
Implementing IPv6 Addressing and Basic Connectivity
Saturday, December 6, 2008
BGP - fast-external-fallover
This feature allows the router to bring a BGP session down when the interface to that peer goes down. If you don't want this or are asked to not allow this to happen, you can disable it:
R1 has a neighbor:
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 188 188 38 0 0 01:56:59 4
R1(config)#int f0/0
R1(config-if)#shut
*Dec 7 03:16:21.270: %BGP-5-ADJCHANGE: neighbor 136.10.12.2 Down Interface flap
We can prevent R1 from tearing the session down by disabling fast-external-fallover:
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 196 194 50 0 0 00:00:03 4
R1(config)#router bgp 100
R1(config-router)#no bgp fast-external-fallover
R1(config-router)#int f0/0
R1(config-if)#shut
R1(config-if)#
*Dec 7 03:19:41.386: %LINK-5-CHANGED: Interface FastEthernet0/0, changed state to administratively down
*Dec 7 03:19:42.386: %LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/0, changed state to down
R1(config-if)#^Z
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 196 194 54 0 0 00:00:50 4
Still up:
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 196 195 54 0 0 00:01:29 4
Now the session will come down when the hold time expires. Some things to remember:
-Only works for directly-connected EBGP peers (hence the word "external" in the command)
-I tested with ebgp-multihop peers and it does not have any effect
-Keepalives are use to bring session down
-Also configurable per-interface with ip bgp fast-external-fallover
R1 has a neighbor:
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 188 188 38 0 0 01:56:59 4
R1(config)#int f0/0
R1(config-if)#shut
*Dec 7 03:16:21.270: %BGP-5-ADJCHANGE: neighbor 136.10.12.2 Down Interface flap
We can prevent R1 from tearing the session down by disabling fast-external-fallover:
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 196 194 50 0 0 00:00:03 4
R1(config)#router bgp 100
R1(config-router)#no bgp fast-external-fallover
R1(config-router)#int f0/0
R1(config-if)#shut
R1(config-if)#
*Dec 7 03:19:41.386: %LINK-5-CHANGED: Interface FastEthernet0/0, changed state to administratively down
*Dec 7 03:19:42.386: %LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/0, changed state to down
R1(config-if)#^Z
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 196 194 54 0 0 00:00:50 4
Still up:
R1#show ip bgp sum | be Ne
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
136.10.12.2 4 200 196 195 54 0 0 00:01:29 4
Now the session will come down when the hold time expires. Some things to remember:
-Only works for directly-connected EBGP peers (hence the word "external" in the command)
-I tested with ebgp-multihop peers and it does not have any effect
-Keepalives are use to bring session down
-Also configurable per-interface with ip bgp fast-external-fallover
IPexpert Volume 2 Section 13 Review - PART I
Well I am 2/3 of the way done here with a couple hours to go, but I am going to finish this next week. I have a terrible cold or something...I don't know, maybe it's all the Hot Pockets I ate this week. Whatever it is...I AM DEFEATED for the day.
I semi-graded this thing and I must say this is the TRICKIEST/HARDEST lab of them all. There are a total of 58 tasks, each worth 1 or 2 points and a few worth 3. This is the longest lab I have ever done to date. I am not entirely sure I would have finished in 8 hours...if I did, I wouldn't have been able to grade or verify much.
I think I missed about 7 or 8 tasks for about 15 or so points so far. Definitely a failed effort, but there were some good lessons learned. Here is a summary of what I had to configure:
-Fallback bridging. I actually got this right
-Only allow NetBIOS over TCP/IP in vlan 999. Used a VACL but I didn't what ports to match for netbios. I used range 135 - 139 but I don't know if this is right.
-Make sure CAT1 never becomes root for VLAN 999. The PG disabled STP for this VLAN, I used bpdufilter on the ports in VLAN 999. The PG was probably more correct.
-If R4 detects PVC states other than invalid, active or inactive - notify the trap receiver. What traps are these??
-Then there was a task that had me configure a secondary address 192.168.80.33/27 on an interface that already belonged to 192.168.80.0/24. Then you were supposed to filter out RIP routes on this subnet - HUH? I have no idea if this was a typo or what but the PG was really bad at explaining this one. I am not going into more detail - see it for yourself :-)
-OSPF task that had two different authentication keys on the same interface. This was a little tricky but I got it to work. I remember seeing this on GS so that helped a lot. You had to use neighbor statements on the spokes instead of the hub.
Anyways. this lab is truly a mind-number. Just the kind of trickery to expect on the lab, I assume. If you think you are hot stuff - try this one ;-)
I semi-graded this thing and I must say this is the TRICKIEST/HARDEST lab of them all. There are a total of 58 tasks, each worth 1 or 2 points and a few worth 3. This is the longest lab I have ever done to date. I am not entirely sure I would have finished in 8 hours...if I did, I wouldn't have been able to grade or verify much.
I think I missed about 7 or 8 tasks for about 15 or so points so far. Definitely a failed effort, but there were some good lessons learned. Here is a summary of what I had to configure:
-Fallback bridging. I actually got this right
-Only allow NetBIOS over TCP/IP in vlan 999. Used a VACL but I didn't what ports to match for netbios. I used range 135 - 139 but I don't know if this is right.
-Make sure CAT1 never becomes root for VLAN 999. The PG disabled STP for this VLAN, I used bpdufilter on the ports in VLAN 999. The PG was probably more correct.
-If R4 detects PVC states other than invalid, active or inactive - notify the trap receiver. What traps are these??
-Then there was a task that had me configure a secondary address 192.168.80.33/27 on an interface that already belonged to 192.168.80.0/24. Then you were supposed to filter out RIP routes on this subnet - HUH? I have no idea if this was a typo or what but the PG was really bad at explaining this one. I am not going into more detail - see it for yourself :-)
-OSPF task that had two different authentication keys on the same interface. This was a little tricky but I got it to work. I remember seeing this on GS so that helped a lot. You had to use neighbor statements on the spokes instead of the hub.
Anyways. this lab is truly a mind-number. Just the kind of trickery to expect on the lab, I assume. If you think you are hot stuff - try this one ;-)
Saturday, November 29, 2008
Mobile ARP
Well seeing as how I just missed a 4-point task on mobile ARP, I thought now was a good time to learn it. It's actually very simple and pretty cool once you get it working.
Topology is a little confusing so here it is in 2 parts:
PHYSICAL:
R1---CAT1===dot1q===CAT2---R8
LOGICAL:
VLAN 100---R1---R2---R5---R7---R8---VLAN 200
The task says that users on R8's LAN occasionally mover over to R1's LAN. They still need access to the network. What we do is configure R1 to listen for ARP packets from R8's subnet (VLAN 200).
We can test this by creating an SVI for VLAN 100 and giving it an IP in R8's subnet. When it tries to contact anyone, we will see a mobile route appear in R1's route table. This route then gets redistributed into the routing protocol (OSPF in this case). It appears as a /32 route so the longer match wins over any other route advertisement of VLAN 200.
All configuration is on R1:
1) CREATE THE ACL
R1(config)#access-list 8 permit 172.31.80.0 0.0.0.255
2) CONFIGURE MOBILE ARP ON INTERFACE
R1(config)#interface f0/0
R1(config-if)# ip mobile arp access-group 8
3) REDISTRIBUTE
R1(config)#router ospf 1
R1(config-router)# redistribute mobile subnets
4) VERIFY
Ceate an SVI on VLAN 100 with VLAN 200 IP address:
CAT1(config)#int vlan 100
CAT1(config-if)#ip address 172.31.80.100 255.255.255.0
CAT1(config-if)#^Z
CAT1#ping 172.31.80.8
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.31.80.8, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 20/219/1016 ms
Run debug and show commands on R1:
R1#debug ip mobile
IP mobility events debugging is on
Nov 29 21:17:14.138: Local MobileIP: route add 172.31.80.100
R1#show ip route mobile
172.31.0.0/16 is variably subnetted, 11 subnets, 6 masks
M 172.31.80.100/32 [3/1] via 172.31.80.100, 00:11:05, FastEthernet0/1
R1#
Traceroute shows how many hops we are actually going through:
CAT1#trace 172.31.80.8
Type escape sequence to abort.
Tracing the route to 172.31.80.8
1 172.31.10.1 4 msec 4 msec 0 msec
2 172.31.12.2 0 msec 4 msec 0 msec
3 172.31.100.5 12 msec 8 msec 12 msec
4 172.31.200.7 12 msec 8 msec 12 msec
5 172.31.78.8 12 msec * 8 msec
CAT1#
Topology is a little confusing so here it is in 2 parts:
PHYSICAL:
R1---CAT1===dot1q===CAT2---R8
LOGICAL:
VLAN 100---R1---R2---R5---R7---R8---VLAN 200
The task says that users on R8's LAN occasionally mover over to R1's LAN. They still need access to the network. What we do is configure R1 to listen for ARP packets from R8's subnet (VLAN 200).
We can test this by creating an SVI for VLAN 100 and giving it an IP in R8's subnet. When it tries to contact anyone, we will see a mobile route appear in R1's route table. This route then gets redistributed into the routing protocol (OSPF in this case). It appears as a /32 route so the longer match wins over any other route advertisement of VLAN 200.
All configuration is on R1:
1) CREATE THE ACL
R1(config)#access-list 8 permit 172.31.80.0 0.0.0.255
2) CONFIGURE MOBILE ARP ON INTERFACE
R1(config)#interface f0/0
R1(config-if)# ip mobile arp access-group 8
3) REDISTRIBUTE
R1(config)#router ospf 1
R1(config-router)# redistribute mobile subnets
4) VERIFY
Ceate an SVI on VLAN 100 with VLAN 200 IP address:
CAT1(config)#int vlan 100
CAT1(config-if)#ip address 172.31.80.100 255.255.255.0
CAT1(config-if)#^Z
CAT1#ping 172.31.80.8
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.31.80.8, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 20/219/1016 ms
Run debug and show commands on R1:
R1#debug ip mobile
IP mobility events debugging is on
Nov 29 21:17:14.138: Local MobileIP: route add 172.31.80.100
R1#show ip route mobile
172.31.0.0/16 is variably subnetted, 11 subnets, 6 masks
M 172.31.80.100/32 [3/1] via 172.31.80.100, 00:11:05, FastEthernet0/1
R1#
Traceroute shows how many hops we are actually going through:
CAT1#trace 172.31.80.8
Type escape sequence to abort.
Tracing the route to 172.31.80.8
1 172.31.10.1 4 msec 4 msec 0 msec
2 172.31.12.2 0 msec 4 msec 0 msec
3 172.31.100.5 12 msec 8 msec 12 msec
4 172.31.200.7 12 msec 8 msec 12 msec
5 172.31.78.8 12 msec * 8 msec
CAT1#
IPexpert Volume 2 Section 12 Review
I woke up late for this one but I still finished in plenty of time. Probably about 4 hours. I made some serious mistakes though that I completely overlooked. It was in the BGP section, I didn't configure a confederation...so that may have ruined 2 or 3 tasks - not real sure how to gauge the impact. You should have seen the look on my face when I saw the PG.
With that included I missed 6 tasks for about 15 points:
-8 Tasks 8.1 - 8.3
I knew we were using private AS numbers so I immediately thought configuring a confederation. However, I did not deduce that from the task requirements so I didn't bother. Reviewing it, I completely overlooked R1's task of peering with R2 is AS 200. AS 200 should have been the confederation....BIG BOOBOO. Completely unacceptable.
-4 Task 9.3 IOS Services
Completely missed this "Mobile ARP" section. I had a NAT solution that does what I thought the task asks. I have no idea how to configure mobile arp and I guess it's time to learn. I wonder if anyone even uses it...
-2 Task 11.2 DHCP
I used "no ip bootp server" for the DHCP router not respond to bootp requests. However, the answer was "ip dhcp bootp ignore"
-1 Task 14.3 Multicast
Configured MRM incorrectly. I used the DocCD for this and was what you could call "way off." It was a 1 point task and I was not too concerned.
My goal from here on out is to keep my score above 80 while improving my "process." That includes verifying everything, making notes and a point tracker, refraining from marking the actual lab docs (which I heard you cannot do), and moving through the DocCD.
Missing the BGP confederation is something that should never happen. I am lucky there were not more tasks dependent on it. Everything else was filtering of some sort. Who knows, I may have been marked of on the entire BGP section (20 points).
One thing I worry about is that I have not really been challenged during Layer 2 configurations. I pretty much breeze through VTP, trunking, and other topics, but I know there are topics that will get me (QoS, tunneling). For these I rely on the DocCD and make my own labs. That being said, Volume 1 Section 5 has an extremely difficult tunneling lab that I need to review.
With that included I missed 6 tasks for about 15 points:
-8 Tasks 8.1 - 8.3
I knew we were using private AS numbers so I immediately thought configuring a confederation. However, I did not deduce that from the task requirements so I didn't bother. Reviewing it, I completely overlooked R1's task of peering with R2 is AS 200. AS 200 should have been the confederation....BIG BOOBOO. Completely unacceptable.
-4 Task 9.3 IOS Services
Completely missed this "Mobile ARP" section. I had a NAT solution that does what I thought the task asks. I have no idea how to configure mobile arp and I guess it's time to learn. I wonder if anyone even uses it...
-2 Task 11.2 DHCP
I used "no ip bootp server" for the DHCP router not respond to bootp requests. However, the answer was "ip dhcp bootp ignore"
-1 Task 14.3 Multicast
Configured MRM incorrectly. I used the DocCD for this and was what you could call "way off." It was a 1 point task and I was not too concerned.
My goal from here on out is to keep my score above 80 while improving my "process." That includes verifying everything, making notes and a point tracker, refraining from marking the actual lab docs (which I heard you cannot do), and moving through the DocCD.
Missing the BGP confederation is something that should never happen. I am lucky there were not more tasks dependent on it. Everything else was filtering of some sort. Who knows, I may have been marked of on the entire BGP section (20 points).
One thing I worry about is that I have not really been challenged during Layer 2 configurations. I pretty much breeze through VTP, trunking, and other topics, but I know there are topics that will get me (QoS, tunneling). For these I rely on the DocCD and make my own labs. That being said, Volume 1 Section 5 has an extremely difficult tunneling lab that I need to review.
Friday, November 28, 2008
BGP - Conditional route injection
Topology
R5----R7
R5 is advertising 10.34.19.0/26 to R7
Configure R7 to inject 10.34.19.48/28
1) MAKE PREFIX-LISTS
ip prefix-list EXIST seq 5 permit 10.34.19.0/26
ip prefix-list INJECT 5 permit 10.34.19.48/28
ip prefix-list SOURCE seq 5 permit 192.168.5.5/32
2) MAKE ROUTE-MAPS
route-map INJECT permit 10
set ip address prefix-list INJECT
route-map EXIST permit 10
match ip address prefix-list EXIST
match ip route-source prefix-list SOURCE
3) CONFIGURE BGP
route bgp 567
bgp inject-map INJECT exist-map EXIST
4) VERIFY
R5#show ip bgp nei 192.168.7.7 advertised-routes | begin Net
Network Next Hop Metric LocPrf Weight Path
*> 10.34.19.0/26 192.168.2.2 0 200 0 24 1 i
R7#show ip bgp injected-paths | begin Net
Network Next Hop Metric LocPrf Weight Path
*>i10.34.19.48/28 192.168.5.5 0 200 0 24 1 i
Things to remember:
- Must use Prefix-lists, NOT ACLs
- Injected route must a subset of am aggregate already in the table
- Use "set" command for inject-map, not "match"
- I commonly forget the "prefix-list" argument when configuring the maps
- inject-map Command is a bgp command, not per-neighbor
R5----R7
R5 is advertising 10.34.19.0/26 to R7
Configure R7 to inject 10.34.19.48/28
1) MAKE PREFIX-LISTS
ip prefix-list EXIST seq 5 permit 10.34.19.0/26
ip prefix-list INJECT 5 permit 10.34.19.48/28
ip prefix-list SOURCE seq 5 permit 192.168.5.5/32
2) MAKE ROUTE-MAPS
route-map INJECT permit 10
set ip address prefix-list INJECT
route-map EXIST permit 10
match ip address prefix-list EXIST
match ip route-source prefix-list SOURCE
3) CONFIGURE BGP
route bgp 567
bgp inject-map INJECT exist-map EXIST
4) VERIFY
R5#show ip bgp nei 192.168.7.7 advertised-routes | begin Net
Network Next Hop Metric LocPrf Weight Path
*> 10.34.19.0/26 192.168.2.2 0 200 0 24 1 i
R7#show ip bgp injected-paths | begin Net
Network Next Hop Metric LocPrf Weight Path
*>i10.34.19.48/28 192.168.5.5 0 200 0 24 1 i
Things to remember:
- Must use Prefix-lists, NOT ACLs
- Injected route must a subset of am aggregate already in the table
- Use "set" command for inject-map, not "match"
- I commonly forget the "prefix-list" argument when configuring the maps
- inject-map Command is a bgp command, not per-neighbor
IPexpert Volume 2 Section 11 Review
I just completed this lab in about 4 or 5 hours. I spent the first hour (before my session even started) reading the lab, redrawing the L3 topology and making a task checklist. This actually took me about a half hour. I got an estimated score of 89, missing 4 tasks for 11 points. Two were easy, but the other two...well, just proof that I need to review the DocCD :-)
Here are the misses:
-3 Task 5.4 EIGRP
Routes should be dropped from inactive neighbors in half the default time. I used hold time command, but the PG had "timers nsf route-hold 120" as the answer. I need to review NSF.
-3 Task 6.1 RIP
I forgot to enable v2-broadcast on one interface. BONEHEAD!
-1 Task 8.7 BGP
Completely misunderstood the aggregation task. BONEHEAD #2!
-4 Task 10.2 DNS
We needed to create a domain list with "ip domain list ipexpert.net". I just used the domain-name command. I am not familiar at all with how DNS resolution works on Cisco routers so I need to review this.
Over the last few months I have increased my speed and efficiency dramatically. Time does not seem to be an issue anymore. When I started studying in the spring, I was taking so long on full scale mock labs, I stopped doing them. Many commands I know by heart, but occasionally I misunderstand a question or just have the wrong command like the EIGRP section above.
Now that I have more time, I use it to prep before I start. This includes reviewing and drawing the topology. I want the processes I use on the practice lab to be just like the ones on the real lab. That way nothing is new and I can get in my comfort zone. I definitely "feel" ready for the real thing, but that doesn't mean I am.
I can still think of some topics that would give me a hard time, unfortunately I haven't seen to many of these lately...but I know they are there...waiting to get me ;-)
Here are the misses:
-3 Task 5.4 EIGRP
Routes should be dropped from inactive neighbors in half the default time. I used hold time command, but the PG had "timers nsf route-hold 120" as the answer. I need to review NSF.
-3 Task 6.1 RIP
I forgot to enable v2-broadcast on one interface. BONEHEAD!
-1 Task 8.7 BGP
Completely misunderstood the aggregation task. BONEHEAD #2!
-4 Task 10.2 DNS
We needed to create a domain list with "ip domain list ipexpert.net". I just used the domain-name command. I am not familiar at all with how DNS resolution works on Cisco routers so I need to review this.
Over the last few months I have increased my speed and efficiency dramatically. Time does not seem to be an issue anymore. When I started studying in the spring, I was taking so long on full scale mock labs, I stopped doing them. Many commands I know by heart, but occasionally I misunderstand a question or just have the wrong command like the EIGRP section above.
Now that I have more time, I use it to prep before I start. This includes reviewing and drawing the topology. I want the processes I use on the practice lab to be just like the ones on the real lab. That way nothing is new and I can get in my comfort zone. I definitely "feel" ready for the real thing, but that doesn't mean I am.
I can still think of some topics that would give me a hard time, unfortunately I haven't seen to many of these lately...but I know they are there...waiting to get me ;-)
Thursday, November 27, 2008
What I'm thankful for - CCIE study edition
In the spirit of this holiday I thought I'd make a list of things that make labbing, studying and the overall process of preparing for the CCIE Lab exam a lot easier. In no particular order:
- Vendor Wars. Great deals are among us!
- Groupstudy. It's taken some criticism lately, but it still remains the best place to brainstorm with fellow CCIE candidates and those that have already passed. And don't forget the archives!
-Ebay. Couldn't have built my lab without it!
- Debug ip packet + ACL. Excellent when you need to debug ip packet but you've got sub-second ospf hello timers. Believe me, I found out the hard way!
- Show access-lists. Easy way to see if you get a hit on an ACL
- Static routes. Just for workarounds while you get reachability in place. I had a ppp task where the router needed an address via dhcp (proxy) but the server couldn't respond unicast to the destination subnet (no route) and no routing protocols were in place yet. Remember to remove them after!
- Colored pencils for each routing protocol. I prefer light green for OSPF, dark green for EIGRP, orange for BGP, black for RIP. I only have 4 colored pencils in my apartment and I put them to good use.
- Regular expressions for parsing show commands with the include, exclude and section arguments.
- Route tagging. Really makes route redistribution a whole lot easier to deal with.
- Master Command index on the DocCD. Nothing short of a life saver sometimes :)
- Trees. A whole lot of scratch paper going on around here...
- And last but not least...Blogrolls!
Well that's my list for now. What are you thankful for?
- Vendor Wars. Great deals are among us!
- Groupstudy. It's taken some criticism lately, but it still remains the best place to brainstorm with fellow CCIE candidates and those that have already passed. And don't forget the archives!
-Ebay. Couldn't have built my lab without it!
- Debug ip packet + ACL. Excellent when you need to debug ip packet but you've got sub-second ospf hello timers. Believe me, I found out the hard way!
- Show access-lists. Easy way to see if you get a hit on an ACL
- Static routes. Just for workarounds while you get reachability in place. I had a ppp task where the router needed an address via dhcp (proxy) but the server couldn't respond unicast to the destination subnet (no route) and no routing protocols were in place yet. Remember to remove them after!
- Colored pencils for each routing protocol. I prefer light green for OSPF, dark green for EIGRP, orange for BGP, black for RIP. I only have 4 colored pencils in my apartment and I put them to good use.
- Regular expressions for parsing show commands with the include, exclude and section arguments.
- Route tagging. Really makes route redistribution a whole lot easier to deal with.
- Master Command index on the DocCD. Nothing short of a life saver sometimes :)
- Trees. A whole lot of scratch paper going on around here...
- And last but not least...Blogrolls!
Well that's my list for now. What are you thankful for?
Tuesday, November 25, 2008
OSPF - Lowest IP address in OSPF is used as forwarding address on ASBR
I was labbing some NSSA today and I was wondering how the OSPF ASBR chose the forward address since it seem to appear on the opposite side of traffic flow. Example:
R3----SW1----R6
SW1 is the ASBR (redistributing it's loopback). Traffic was flowing through R6, but the address pointing to R3 was the "forward address". It doesn't really matter as long as the link is in OSPF but it can impact metric calculations since SW1's interface cost to R3 will be included.
I did a short search on GS and RFC2328 but could not find anything. I had a guess it was the lowest IP in OSPF on the router and it turns out that is right:
SW1#show run | sec router ospf
router ospf 1
router-id 11.11.11.11
log-adjacency-changes
area 2 nssa
redistribute connected metric-type 1 subnets route-map con2ospf
network 2.0.0.1 0.0.0.0 area 2
network 192.168.37.7 0.0.0.0 area 2
network 192.168.67.7 0.0.0.0 area 2
SW1#show ip int bri
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 192.168.37.7 YES manual up up
FastEthernet2/0 192.168.67.7 YES manual up up
Loopback2 2.0.0.1 YES manual up up
Loopback100 100.100.100.100 YES manual up up
SW1#show ip ospf database external
OSPF Router with ID (11.11.11.11) (Process ID 1)
SW1#show ip ospf database ns
SW1#show ip ospf database nssa-external
OSPF Router with ID (11.11.11.11) (Process ID 1)
Type-7 AS External Link States (Area 2)
LS age: 243
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 100.100.100.100 (External Network Number )
Advertising Router: 11.11.11.11
LS Seq Number: 80000009
Checksum: 0x8EBF
Length: 36
Network Mask: /32
Metric Type: 1 (Comparable directly to link state metric)
TOS: 0
Metric: 20
Forward Address: 2.0.0.1
External Route Tag: 0
SW1#
R3----SW1----R6
SW1 is the ASBR (redistributing it's loopback). Traffic was flowing through R6, but the address pointing to R3 was the "forward address". It doesn't really matter as long as the link is in OSPF but it can impact metric calculations since SW1's interface cost to R3 will be included.
I did a short search on GS and RFC2328 but could not find anything. I had a guess it was the lowest IP in OSPF on the router and it turns out that is right:
SW1#show run | sec router ospf
router ospf 1
router-id 11.11.11.11
log-adjacency-changes
area 2 nssa
redistribute connected metric-type 1 subnets route-map con2ospf
network 2.0.0.1 0.0.0.0 area 2
network 192.168.37.7 0.0.0.0 area 2
network 192.168.67.7 0.0.0.0 area 2
SW1#show ip int bri
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 192.168.37.7 YES manual up up
FastEthernet2/0 192.168.67.7 YES manual up up
Loopback2 2.0.0.1 YES manual up up
Loopback100 100.100.100.100 YES manual up up
SW1#show ip ospf database external
OSPF Router with ID (11.11.11.11) (Process ID 1)
SW1#show ip ospf database ns
SW1#show ip ospf database nssa-external
OSPF Router with ID (11.11.11.11) (Process ID 1)
Type-7 AS External Link States (Area 2)
LS age: 243
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 100.100.100.100 (External Network Number )
Advertising Router: 11.11.11.11
LS Seq Number: 80000009
Checksum: 0x8EBF
Length: 36
Network Mask: /32
Metric Type: 1 (Comparable directly to link state metric)
TOS: 0
Metric: 20
Forward Address: 2.0.0.1
External Route Tag: 0
SW1#
Monday, November 24, 2008
Routing Loop - Part I
I was reading "Optimal Routing Design" by Cisco Press today and a routing loop scenario was described (chapter 2), but they had it all wrong and screwy and it gave me a routing loop in my brain. So I wanted to actually do a similar scenario some justice. This hopefully will be first part in maybe a series of posts that deal with routing loops, since they can be real buggers.
The Topology:

The Scenario:
R2 is hub with R5 and R6 as OSPF neighbors.
R5 and R6 are also EIGRP neighbors with R7.
R7 is redistributing it's serial interface with R8 into the EIGRP domain.
R5 and R6 are mutually redistributing between OSPF and EIGRP.
If R5 and R6 redistribute OSPF into EIGRP with equal metrics, everything stabilizes, even though you have a suboptimal path. This is because External OSPF (AD=110) is preferred over External EIGRP (AD=170). So whichever device (R5 or R6) redistributes R7's serial network into OSPF first, will keep it's route via EIGRP but the other router will learn it via OSPF.
Let's take a look at R5 and R6 OSPF and EIGRP config (there both the same):
R5#show run | sec router ospf|eigrp
router eigrp 1
redistribute ospf 1 metric 1 1 1 1 1
network 150.100.0.0
no auto-summary
router ospf 1
log-adjacency-changes
redistribute eigrp 1 subnets
network 150.100.100.0 0.0.0.255 area 0
R5#
This results in the following route entries for 150.100.78.0
R5#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 128
Redistributing via eigrp 1
Advertised by eigrp 1 metric 1 1 1 1 1
Last update from 150.100.100.2 on Serial1/0, 00:10:23 ago
Routing Descriptor Blocks:
* 150.100.100.2, from 6.6.6.6, 00:10:23 ago, via Serial1/0
Route metric is 20, traffic share count is 1
R6#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 2560002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.7 on FastEthernet0/0, 00:01:21 ago
Routing Descriptor Blocks:
150.100.56.7, from 150.100.56.7, 00:01:21 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
* 150.100.56.5, from 150.100.56.5, 00:01:21 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
R2#trace 150.100.78.7
Type escape sequence to abort.
Tracing the route to 150.100.78.7
1 150.100.100.6 76 msec 72 msec 20 msec
2 150.100.56.7 48 msec * 72 msec
R2#
Notice that R5 has learned the route via OSPF and has advertised it back into EIGRP with the same metric that R7 is originally advertising it with. R6 has installed them both. So far it's not impacting anything.
Now let's suppose we had a task that said R7 should prefer R5 to reach the OSPF domain and you must configure the solution on R5. How could we do that? We could adjust the metric when redistributing. Let's do this by increasing the bandwidth metric on R5:
R5(config)#router eigrp 1
R5(config-router)#redistribute ospf 1 metric 2 1 1 1 1
Now let's look at R6's entry:
R6#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 1280002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.5 on FastEthernet0/0, 00:01:37 ago
Routing Descriptor Blocks:
* 150.100.56.5, from 150.100.56.5, 00:01:37 ago, via FastEthernet0/0
Route metric is 1280002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 2 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
Its' pointing back to R5!! Let's look at R5:
R5#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 128
Redistributing via eigrp 1
Advertised by eigrp 1 metric 2 1 1 1 1
Last update from 150.100.100.2 on Serial1/0, 00:15:35 ago
Routing Descriptor Blocks:
* 150.100.100.2, from 6.6.6.6, 00:15:35 ago, via Serial1/0
Route metric is 20, traffic share count is 1
It's still pointing to R2!! Trace from R2:
R2#trace 150.100.78.7
Type escape sequence to abort.
Tracing the route to 150.100.78.7
1 150.100.100.6 40 msec 76 msec 16 msec
2 150.100.56.5 96 msec 28 msec 44 msec
3 150.100.100.2 44 msec 36 msec 44 msec
4 * * *
5 * * *
6 * * *
So...how would you fix it?
R5 and R6 should learn this route via EIGRP...but last time I tried you could not alter AD for specific external routes...but you can do it for OSPF.
access-list 78 permit 150.100.78.0 0.0.0.255
router ospf 1
distance 180 0.0.0.0 255.255.255.255 78
Now the OSPF route will never be preffered but we do have failover should R5 or R6 lose its LAN connection. Doing this on one side actually fixes it, but leaves R6 with a suboptimal route. I prefer to do it on both.
Final verification of the solution:
R5#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 2560002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.7 on FastEthernet0/0, 00:00:16 ago
Routing Descriptor Blocks:
* 150.100.56.7, from 150.100.56.7, 00:00:16 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
R6#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 2560002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.7 on FastEthernet0/0, 00:00:12 ago
Routing Descriptor Blocks:
* 150.100.56.7, from 150.100.56.7, 00:00:12 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
2#trace 150.100.78.7
Type escape sequence to abort.
Tracing the route to 150.100.78.7
1 150.100.100.6 44 msec
150.100.100.5 104 msec
150.100.100.6 20 msec
2 150.100.56.7 56 msec * 72 msec
R2#
If you know any other scenarios, please let me know.
The Topology:

The Scenario:
R2 is hub with R5 and R6 as OSPF neighbors.
R5 and R6 are also EIGRP neighbors with R7.
R7 is redistributing it's serial interface with R8 into the EIGRP domain.
R5 and R6 are mutually redistributing between OSPF and EIGRP.
If R5 and R6 redistribute OSPF into EIGRP with equal metrics, everything stabilizes, even though you have a suboptimal path. This is because External OSPF (AD=110) is preferred over External EIGRP (AD=170). So whichever device (R5 or R6) redistributes R7's serial network into OSPF first, will keep it's route via EIGRP but the other router will learn it via OSPF.
Let's take a look at R5 and R6 OSPF and EIGRP config (there both the same):
R5#show run | sec router ospf|eigrp
router eigrp 1
redistribute ospf 1 metric 1 1 1 1 1
network 150.100.0.0
no auto-summary
router ospf 1
log-adjacency-changes
redistribute eigrp 1 subnets
network 150.100.100.0 0.0.0.255 area 0
R5#
This results in the following route entries for 150.100.78.0
R5#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 128
Redistributing via eigrp 1
Advertised by eigrp 1 metric 1 1 1 1 1
Last update from 150.100.100.2 on Serial1/0, 00:10:23 ago
Routing Descriptor Blocks:
* 150.100.100.2, from 6.6.6.6, 00:10:23 ago, via Serial1/0
Route metric is 20, traffic share count is 1
R6#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 2560002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.7 on FastEthernet0/0, 00:01:21 ago
Routing Descriptor Blocks:
150.100.56.7, from 150.100.56.7, 00:01:21 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
* 150.100.56.5, from 150.100.56.5, 00:01:21 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
R2#trace 150.100.78.7
Type escape sequence to abort.
Tracing the route to 150.100.78.7
1 150.100.100.6 76 msec 72 msec 20 msec
2 150.100.56.7 48 msec * 72 msec
R2#
Notice that R5 has learned the route via OSPF and has advertised it back into EIGRP with the same metric that R7 is originally advertising it with. R6 has installed them both. So far it's not impacting anything.
Now let's suppose we had a task that said R7 should prefer R5 to reach the OSPF domain and you must configure the solution on R5. How could we do that? We could adjust the metric when redistributing. Let's do this by increasing the bandwidth metric on R5:
R5(config)#router eigrp 1
R5(config-router)#redistribute ospf 1 metric 2 1 1 1 1
Now let's look at R6's entry:
R6#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 1280002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.5 on FastEthernet0/0, 00:01:37 ago
Routing Descriptor Blocks:
* 150.100.56.5, from 150.100.56.5, 00:01:37 ago, via FastEthernet0/0
Route metric is 1280002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 2 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
Its' pointing back to R5!! Let's look at R5:
R5#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 128
Redistributing via eigrp 1
Advertised by eigrp 1 metric 2 1 1 1 1
Last update from 150.100.100.2 on Serial1/0, 00:15:35 ago
Routing Descriptor Blocks:
* 150.100.100.2, from 6.6.6.6, 00:15:35 ago, via Serial1/0
Route metric is 20, traffic share count is 1
It's still pointing to R2!! Trace from R2:
R2#trace 150.100.78.7
Type escape sequence to abort.
Tracing the route to 150.100.78.7
1 150.100.100.6 40 msec 76 msec 16 msec
2 150.100.56.5 96 msec 28 msec 44 msec
3 150.100.100.2 44 msec 36 msec 44 msec
4 * * *
5 * * *
6 * * *
So...how would you fix it?
R5 and R6 should learn this route via EIGRP...but last time I tried you could not alter AD for specific external routes...but you can do it for OSPF.
access-list 78 permit 150.100.78.0 0.0.0.255
router ospf 1
distance 180 0.0.0.0 255.255.255.255 78
Now the OSPF route will never be preffered but we do have failover should R5 or R6 lose its LAN connection. Doing this on one side actually fixes it, but leaves R6 with a suboptimal route. I prefer to do it on both.
Final verification of the solution:
R5#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 2560002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.7 on FastEthernet0/0, 00:00:16 ago
Routing Descriptor Blocks:
* 150.100.56.7, from 150.100.56.7, 00:00:16 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
R6#show ip route 150.100.78.0
Routing entry for 150.100.78.0/24
Known via "eigrp 1", distance 170, metric 2560002816, type external
Redistributing via eigrp 1, ospf 1
Advertised by ospf 1 subnets
Last update from 150.100.56.7 on FastEthernet0/0, 00:00:12 ago
Routing Descriptor Blocks:
* 150.100.56.7, from 150.100.56.7, 00:00:12 ago, via FastEthernet0/0
Route metric is 2560002816, traffic share count is 1
Total delay is 110 microseconds, minimum bandwidth is 1 Kbit
Reliability 1/255, minimum MTU 1 bytes
Loading 1/255, Hops 1
2#trace 150.100.78.7
Type escape sequence to abort.
Tracing the route to 150.100.78.7
1 150.100.100.6 44 msec
150.100.100.5 104 msec
150.100.100.6 20 msec
2 150.100.56.7 56 msec * 72 msec
R2#
If you know any other scenarios, please let me know.
Subscribe to:
Posts (Atom)

